Poglavje 2 Urejeni in relacijski podatki
Pri kakršnemkoli delu smo običajno zelo ciljno naravnani. Dobimo nalogo in jo želimo čimprej in čimbolje opraviti. Z namenom učinkovitosti se običajno poslužimo znanih orodij in postopkov, ki jih prilagodimo samemu problemu. Pri delu s podatki se ciljna naravnanost običajno izrazi tako, da želimo čimprej priti do analize in zaključkov, samemu urejanju podatkov pa ne posvetimo pretirane pozornosti, oziroma le toliko, kot je nujno potrebno (kar je še vedno lahko dolgotrajno). Na kratek rok to deluje v redu in celo prihranimo nekaj časa. Na dolgi rok pa običajno zahteva veliko več časa, saj se moramo pri vsaki novi nalogi na novo prilagajati podatkom. Boljši pristop bi bil, da bi problem prilagodili ustaljenemu postopku. Običajno lahko večino podatkov uredimo do te mere, da so si po obliki podobni. V kolikor se naučimo narediti to za neko splošno podatkovno zbirko, lahko potem vsakič pristopimo do nadaljnjega dela na podoben način. V praksi s tem na dolgi rok prihranimo veliko časa.
Koncept urejenih podatkov (ang. tidy data), ki ga bomo spoznali v tem poglavju, je formalizacija intuitivne predstavke kaj podatki so. Podatke, ki so urejeni, lahko veliko lažje transformiramo in pripravimo na nadaljnjo analizo. Tudi funkcije v tidyverse so implementirane tako, da na vhod prejmejo urejene podatke in takšne tudi vrnejo. Z drugimi besedami ohranjajo urejenost.
Relacijski podatki pa so podatki o različnih entitetah (na primer podjetje, delavec, službeno vozilo, klient), ki so shranjeni v različnih razpredelnicah. Kadar želimo analizirati relacijske podatke moramo razumeti povezave med njimi in kako delati z njimi. Spoznali bomo koncept relacijskih podatkovnih zbirk in kako uporabiti tidyverse za delo z njimi.
2.1 Priprava
V tem poglavju bomo spoznali, kako podatke pretvorimo iz daljše v krajšo obliko (in obratno) ter kako delamo z relacijskimi podatki. Kaj vsi ti koncepti pomenijo in kako so povezani z urejenimi podatki, bomo predelali v jedru poglavja.
Pri pretvorbi podatkov v daljšo obliko gre za pretvorbo, kjer vrednosti večih stolpcev združimo v en stolpec. Poglejmo si razpredelnico, kjer imamo shranjene podatke za več let:
df <- tibble(
ime = c("Mojca", "Miha", "Mateja"),
`2018` = c(5.5, 4.6, 8.7),
`2019` = c(5.8, 4.2, 9)
)
df## # A tibble: 3 x 3
## ime `2018` `2019`
## <chr> <dbl> <dbl>
## 1 Mojca 5.5 5.8
## 2 Miha 4.6 4.2
## 3 Mateja 8.7 9Recimo, da želimo stolpca z leti spraviti v en stolpec. Uporabimo funkcijo pivot_longer().
df_longer <- pivot_longer(df, c(`2018`, `2019`), names_to = "leto", values_to = "rezultat")
df_longer## # A tibble: 6 x 3
## ime leto rezultat
## <chr> <chr> <dbl>
## 1 Mojca 2018 5.5
## 2 Mojca 2019 5.8
## 3 Miha 2018 4.6
## 4 Miha 2019 4.2
## 5 Mateja 2018 8.7
## 6 Mateja 2019 9Lahko naredimo tudi obratno transformacijo, torej da vrednosti enega stolpca razširimo v več stolpcev. Na primer, razširimo stolpec ime:
pivot_wider(df_longer, names_from = ime, values_from = rezultat)## # A tibble: 2 x 4
## leto Mojca Miha Mateja
## <chr> <dbl> <dbl> <dbl>
## 1 2018 5.5 4.6 8.7
## 2 2019 5.8 4.2 9Naloga: Spodnjo razpredelnico transformirajte v daljšo obliko, tako da informacije o številu oddelkov shranite v 1 stolpec.
df <- tibble(
podjetje = c("Podjetje A", "Podjetje A", "Podjetje B"),
kraj_tovarne = c("Koper", "Kranj", "Koper"),
prihodek = c(100000, 120000, 60000),
razvojni_oddelki = c(2, 3, 1),
prodajni_oddelki = c(3, 3, 2)
)
df## # A tibble: 3 x 5
## podjetje kraj_tovarne prihodek razvojni_oddelki prodajni_oddelki
## <chr> <chr> <dbl> <dbl> <dbl>
## 1 Podjetje A Koper 100000 2 3
## 2 Podjetje A Kranj 120000 3 3
## 3 Podjetje B Koper 60000 1 2Rešitev:
## # A tibble: 6 x 5
## podjetje kraj_tovarne prihodek oddelek stevilo_oddelkov
## <chr> <chr> <dbl> <chr> <dbl>
## 1 Podjetje A Koper 100000 razvojni_oddelki 2
## 2 Podjetje A Koper 100000 prodajni_oddelki 3
## 3 Podjetje A Kranj 120000 razvojni_oddelki 3
## 4 Podjetje A Kranj 120000 prodajni_oddelki 3
## 5 Podjetje B Koper 60000 razvojni_oddelki 1
## 6 Podjetje B Koper 60000 prodajni_oddelki 2Spoznali bomo tudi relacijske podatke, pri katerih so podatki razdeljeni med več razpredelnic. Zato bomo potrebovali več funkcij, ki nam omogočajo združevanje teh razpredelnic. Poglejmo si dve razpredelnici:
ekipe <- tibble(
id_ekipe = c(1, 2, 3, 4),
ekipa = c("Liverpool", "Manchester United", "Arsenal", "Rokova ekipa")
)
igralci <- tibble(
id_igralca = c(1, 2, 3, 4, 5, 6, 7),
ime = c("Henderson", "Fernandes", "Alisson", "Rashford", "Novak", "Aubameyang", "Vega"),
id_ekipe = c(1, 2, 1, 2, 8, 3, 8)
)
ekipe## # A tibble: 4 x 2
## id_ekipe ekipa
## <dbl> <chr>
## 1 1 Liverpool
## 2 2 Manchester United
## 3 3 Arsenal
## 4 4 Rokova ekipaigralci## # A tibble: 7 x 3
## id_igralca ime id_ekipe
## <dbl> <chr> <dbl>
## 1 1 Henderson 1
## 2 2 Fernandes 2
## 3 3 Alisson 1
## 4 4 Rashford 2
## 5 5 Novak 8
## 6 6 Aubameyang 3
## 7 7 Vega 8Za združevanje razpredelnic obstaja več funkcij, vse imajo končnico _join. Poglejmo si, kako jih kličemo in kaj vsaka izmed njih naredi. Več bomo o njih povedali na predavanju.
left_join() združi razpredelnici tako, da obdrži vse primere iz prve razpredelnice:
left_join(igralci, ekipe, by = "id_ekipe")## # A tibble: 7 x 4
## id_igralca ime id_ekipe ekipa
## <dbl> <chr> <dbl> <chr>
## 1 1 Henderson 1 Liverpool
## 2 2 Fernandes 2 Manchester United
## 3 3 Alisson 1 Liverpool
## 4 4 Rashford 2 Manchester United
## 5 5 Novak 8 <NA>
## 6 6 Aubameyang 3 Arsenal
## 7 7 Vega 8 <NA>right_join() združi razpredelnici tako, da obdrži vse primere iz druge razpredelnice:
right_join(igralci, ekipe, by = "id_ekipe")## # A tibble: 6 x 4
## id_igralca ime id_ekipe ekipa
## <dbl> <chr> <dbl> <chr>
## 1 1 Henderson 1 Liverpool
## 2 2 Fernandes 2 Manchester United
## 3 3 Alisson 1 Liverpool
## 4 4 Rashford 2 Manchester United
## 5 6 Aubameyang 3 Arsenal
## 6 NA <NA> 4 Rokova ekipainner_join() združi razpredelnici tako, da obdrži samo primere, ki se pojavijo v obeh razpredelnicah:
inner_join(igralci, ekipe, by = "id_ekipe")## # A tibble: 5 x 4
## id_igralca ime id_ekipe ekipa
## <dbl> <chr> <dbl> <chr>
## 1 1 Henderson 1 Liverpool
## 2 2 Fernandes 2 Manchester United
## 3 3 Alisson 1 Liverpool
## 4 4 Rashford 2 Manchester United
## 5 6 Aubameyang 3 Arsenalfull_join() združi razpredelnici tako, da obdrži vse primere iz obeh razpredelnic:
full_join(igralci, ekipe, by = "id_ekipe")## # A tibble: 8 x 4
## id_igralca ime id_ekipe ekipa
## <dbl> <chr> <dbl> <chr>
## 1 1 Henderson 1 Liverpool
## 2 2 Fernandes 2 Manchester United
## 3 3 Alisson 1 Liverpool
## 4 4 Rashford 2 Manchester United
## 5 5 Novak 8 <NA>
## 6 6 Aubameyang 3 Arsenal
## 7 7 Vega 8 <NA>
## 8 NA <NA> 4 Rokova ekipaNaloga: Obstajata še dve operaciji združevanja, ki pa ne delujeta popolnoma enako kot zgornje funkcije. Pokličite funkciji semi_join() in anti_join() in poizkusite ugotoviti, kaj sta ti funkciji naredili. Sintaksa je enaka kot pri ostalih funkcijah join.
Za branje podatkov iz tekstovnih datotek velikokrat uporabljamo funkcijo read.csv() ali katero od preostalih izpeljank funkcije read.table(). Tidyverse ima svojo različico teh funkcij, ki pa imajo nekaj dodatne funkcionalnosti. Najbolj pomembna je ta, da se podatki samodejno shranijo kot tibble. To omogoča relativno enostavno branje datotek, kjer stolpci niso poimenovani v skladu s pravili programskega jezika R (na primer, lahko se začnejo s številom, lahko imajo minuse, presledke in podobno). Kot smo omenili shranjevanje podatkov, kjer imena stolpcev niso standardne oblike, ni dobra praksa. Vsekakor pa se pri realnih podatkih velikokrat zgodi, da imamo takšna imena. V tem primeru je bolje, da jih prebermo takšna kot so in jih programsko spremenimo, saj s tem ne posegamo v izvirne podatke. Je pa potrebno pri teh funkcijah dodatno nastaviti kodiranje, da znajo prebrati šumnike. Poglejmo si uporabo funkcije read_csv2() paketa readr, kjer bomo ustrezno nastavili kodiranje.
df <- read_csv2("./data-raw/SLO-gradbena-dovoljenja-messy1.csv",
locale = readr::locale(encoding = "cp1250"))Več o kodiranjih bomo povedali na zadnjem predavanju.
2.2 Urejeni podatki
Omenili smo že, da se v praksi srečamo z najrazličnejšimi oblikami zapisov podatkov. Skupek paketov tidyverse je namenjen delu s tako imenovanimi urejenimi podatki (ang. tidy data). Ideja je, da se ustvari enoten standard za obliko podatkov, s katero je lažje delati. V kolikor se držimo tega standarda pri vseh naših analizah, nam to omogoča, da vedno uporabljamo ista orodja (na primer, ggplot2) in se nam ni potrebno učiti novih orodij za vsako analizo. Standard lahko povzamemo s 3 lastnostmi:
- vsak stolpec je spremenljivka,
- vsaka vrstica je primer podatka,
- vsaka vrednost ima svojo celico.
Morda se na tej točki to sliši nekoliko abstraktno. Poglejmo si praktičen primer. Nabrali smo podatke o številu izdanih gradbenih dovoljenj v Sloveniji, razdeljeno glede na občine. Podatke smo prenesli s spletne strani statističnega urada Slovenije https://pxweb.stat.si/SiStat/slshranili in jih shranili na več načinov. Najprej si poglejmo podatke v takšni obliki, kot smo jih dobili naravnost iz vira.
## # A tibble: 424 x 16
## OBČINE TIP.STAVBE `2007` `2008` `2009` `2010` `2011` `2012` `2013` `2014`
## <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Ajdovšč~ Stanovanjsk~ 52 55 45 33 52 40 29 30
## 2 Ajdovšč~ Nestanovanj~ 19 9 22 15 27 11 23 11
## 3 Ankaran~ Stanovanjsk~ NA NA NA NA NA NA NA NA
## 4 Ankaran~ Nestanovanj~ NA NA NA NA NA NA NA NA
## 5 Apače Stanovanjsk~ 10 11 22 12 7 5 9 10
## 6 Apače Nestanovanj~ 3 3 8 3 4 6 2 3
## 7 Beltinci Stanovanjsk~ 16 19 11 15 19 14 5 13
## 8 Beltinci Nestanovanj~ 4 6 1 3 8 4 4 5
## 9 Benedikt Stanovanjsk~ 11 12 6 9 7 3 16 10
## 10 Benedikt Nestanovanj~ 3 2 1 3 5 3 4 3
## # ... with 414 more rows, and 6 more variables: 2015 <dbl>, 2016 <dbl>,
## # 2017 <dbl>, 2018 <dbl>, 2019 <dbl>, 2020 <dbl>Najprej imamo na voljo spremenljivki OBČINE in TIP.STAVBE. Potem pa imamo za vsako leto naštete vrednosti, oziroma števila gradbenih dovoljenj. Podatki so velikokrat shranjeni v takšnem formatu, saj ima določene prednosti. Tak format je bolj prijazen za prikaz človeku, saj lahko samo s pogledom na razpredelnico hitro oceni, ali obstaja trend v posamezni vrstici. Format pa ni najboljši za delo s podatki. Govorili smo že o čistih podatkih in da vse funkcije v tidyverse podpirajo operacije nad takšnimi podatki. Kot vhod bo večina teh funkcij prejela čiste podatke in takšne potem tudi vrnila.
Kaj je razlog, da ti podatki niso čisti? Ne drži, da imamo v vsakem stolpcu spremenljivko, saj imamo eno spremenljivko razvlečeno čez več stolpcev – leto. Ta podatek vsekakor predstavlja spremenljivko, torej bi moral imeti enoten stolpec. Poglejmo si te podatke še v dveh nečistih formatih.
## # A tibble: 28 x 214
## TIP.STAVBE Leto Ajdovščina `Ankaran/Ancaran~ Apače Beltinci Benedikt
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Stanovanjske stav~ 2007 52 NA 10 16 11
## 2 Stanovanjske stav~ 2008 55 NA 11 19 12
## 3 Stanovanjske stav~ 2009 45 NA 22 11 6
## 4 Stanovanjske stav~ 2010 33 NA 12 15 9
## 5 Stanovanjske stav~ 2011 52 NA 7 19 7
## 6 Stanovanjske stav~ 2012 40 NA 5 14 3
## 7 Stanovanjske stav~ 2013 29 NA 9 5 16
## 8 Stanovanjske stav~ 2014 30 NA 10 13 10
## 9 Stanovanjske stav~ 2015 38 3 12 23 13
## 10 Stanovanjske stav~ 2016 31 1 10 22 15
## # ... with 18 more rows, and 207 more variables: Bistrica ob Sotli <dbl>,
## # Bled <dbl>, Bloke <dbl>, Bohinj <dbl>, Borovnica <dbl>, Bovec <dbl>,
## # Braslovče <dbl>, Brda <dbl>, Brezovica <dbl>, Brežice <dbl>, Cankova <dbl>,
## # Celje <dbl>, Cerklje na Gorenjskem <dbl>, Cerknica <dbl>, Cerkno <dbl>,
## # Cerkvenjak <dbl>, Cirkulane <dbl>, Črenšovci <dbl>, Črna na Koroškem <dbl>,
## # Črnomelj <dbl>, Destrnik <dbl>, Divača <dbl>, Dobje <dbl>,
## # Dobrepolje <dbl>, Dobrna <dbl>, Dobrova - Polhov Gradec <dbl>,
## # Dobrovnik/Dobronak <dbl>, Dol pri Ljubljani <dbl>, Dolenjske Toplice <dbl>,
## # Domžale <dbl>, Dornava <dbl>, Dravograd <dbl>, Duplek <dbl>,
## # Gorenja vas - Poljane <dbl>, Gorišnica <dbl>, Gorje <dbl>,
## # Gornja Radgona <dbl>, Gornji Grad <dbl>, Gornji Petrovci <dbl>, Grad <dbl>,
## # Grosuplje <dbl>, Hajdina <dbl>, Hoče - Slivnica <dbl>, Hodoš/Hodos <dbl>,
## # Horjul <dbl>, Hrastnik <dbl>, Hrpelje - Kozina <dbl>, Idrija <dbl>,
## # Ig <dbl>, Ilirska Bistrica <dbl>, Ivančna Gorica <dbl>, Izola/Isola <dbl>,
## # Jesenice <dbl>, Jezersko <dbl>, Juršinci <dbl>, Kamnik <dbl>, Kanal <dbl>,
## # Kidričevo <dbl>, Kobarid <dbl>, Kobilje <dbl>, Kočevje <dbl>, Komen <dbl>,
## # Komenda <dbl>, Koper/Capodistria <dbl>, Kostanjevica na Krki <dbl>,
## # Kostel <dbl>, Kozje <dbl>, Kranj <dbl>, Kranjska Gora <dbl>,
## # Križevci <dbl>, Krško <dbl>, Kungota <dbl>, Kuzma <dbl>, Laško <dbl>,
## # Lenart <dbl>, Lendava/Lendva <dbl>, Litija <dbl>, Ljubljana <dbl>,
## # Ljubno <dbl>, Ljutomer <dbl>, Log - Dragomer <dbl>, Logatec <dbl>,
## # Loška dolina <dbl>, Loški Potok <dbl>, Lovrenc na Pohorju <dbl>,
## # Luče <dbl>, Lukovica <dbl>, Majšperk <dbl>, Makole <dbl>, Maribor <dbl>,
## # Markovci <dbl>, Medvode <dbl>, Mengeš <dbl>, Metlika <dbl>, Mežica <dbl>,
## # Miklavž na Dravskem polju <dbl>, Miren - Kostanjevica <dbl>, Mirna <dbl>,
## # Mirna Peč <dbl>, Mislinja <dbl>, ...Sedaj imamo podobno situacijo kot prej – ena spremenljivka je razvlečena preko več stolpcev – v tem primeru je to občina. Kot smo že omenili, so vsaki nečisti podatki nečisti na svoj način. Podatki so popolnoma enaki kot v prejšnjem prikazu, ampak razpredelnica izgleda popolnoma drugače. Čisti podatki pa imajo samo eno pravilno obliko, torej ne more priti do takšnih dvoumnih prikazov.
Poglejmo si še tretji format:
## # A tibble: 5,936 x 3
## OBČINA_TIP Leto Število.gradbenih.dovoljenj
## <chr> <dbl> <dbl>
## 1 Ajdovščina_Stanovanjske stavbe 2007 52
## 2 Ajdovščina_Stanovanjske stavbe 2008 55
## 3 Ajdovščina_Stanovanjske stavbe 2009 45
## 4 Ajdovščina_Stanovanjske stavbe 2010 33
## 5 Ajdovščina_Stanovanjske stavbe 2011 52
## 6 Ajdovščina_Stanovanjske stavbe 2012 40
## 7 Ajdovščina_Stanovanjske stavbe 2013 29
## 8 Ajdovščina_Stanovanjske stavbe 2014 30
## 9 Ajdovščina_Stanovanjske stavbe 2015 38
## 10 Ajdovščina_Stanovanjske stavbe 2016 31
## # ... with 5,926 more rowsTa je morda nekoliko bližje čistim podatkom, kot prejšnja dva, ampak še vedno ni v popolnoma pravilni obliki. V čem je težava? Dve spremenljivki imamo podani v enem stolpcu – občino in tip. Ker gre za različni spremenljivki, bi bilo dobro, da se pojavita v različnih stolpcih.
Poglejmo si sedaj še čiste podatke:
## # A tibble: 5,936 x 4
## OBČINE TIP.STAVBE Leto Število.gradbenih.dovoljenj
## <chr> <chr> <dbl> <dbl>
## 1 Ajdovščina Stanovanjske stavbe 2007 52
## 2 Ajdovščina Stanovanjske stavbe 2008 55
## 3 Ajdovščina Stanovanjske stavbe 2009 45
## 4 Ajdovščina Stanovanjske stavbe 2010 33
## 5 Ajdovščina Stanovanjske stavbe 2011 52
## 6 Ajdovščina Stanovanjske stavbe 2012 40
## 7 Ajdovščina Stanovanjske stavbe 2013 29
## 8 Ajdovščina Stanovanjske stavbe 2014 30
## 9 Ajdovščina Stanovanjske stavbe 2015 38
## 10 Ajdovščina Stanovanjske stavbe 2016 31
## # ... with 5,926 more rowsSedaj ima vsaka spremenljivka (občina, tip in leto) svoj stolpec, zadnji stolpec pa je namenjen vrednostim. V tem poglavju se bomo naučili nečiste podatke spremeniti v čiste.
Čisti podatki imajo običajno več vrstic kot nečisti in jim zato pravimo da so daljši (ang. longer). Nečisti pa so običajno širši (ang. wider). Izogibamo se besedam dolgi in široki, saj je ta definicija relativna, se pravi lahko uporabimo transformacijo, ki naredi podatke daljše, ne pa nujno dolge, saj morda obstaja še kakšna operacija, ki jih bo naredila še daljše.
2.3 pivot_longer(): pretvorba v daljšo obliko
Funkcija pivot_longer() podatke spremeni v daljšo obliko. Ta trasformacija je pri delu s podatki bolj pogosta kot sprememba v širšo. Običajno uporabljamo to transformacijo, ko preurejamo podatke v čiste.
Poglejmo si ponovno nečiste podatke, ki smo jih dobili naravnost iz vira:
## # A tibble: 424 x 16
## OBČINE TIP.STAVBE `2007` `2008` `2009` `2010` `2011` `2012` `2013` `2014`
## <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Ajdovšč~ Stanovanjsk~ 52 55 45 33 52 40 29 30
## 2 Ajdovšč~ Nestanovanj~ 19 9 22 15 27 11 23 11
## 3 Ankaran~ Stanovanjsk~ NA NA NA NA NA NA NA NA
## 4 Ankaran~ Nestanovanj~ NA NA NA NA NA NA NA NA
## 5 Apače Stanovanjsk~ 10 11 22 12 7 5 9 10
## 6 Apače Nestanovanj~ 3 3 8 3 4 6 2 3
## 7 Beltinci Stanovanjsk~ 16 19 11 15 19 14 5 13
## 8 Beltinci Nestanovanj~ 4 6 1 3 8 4 4 5
## 9 Benedikt Stanovanjsk~ 11 12 6 9 7 3 16 10
## 10 Benedikt Nestanovanj~ 3 2 1 3 5 3 4 3
## # ... with 414 more rows, and 6 more variables: 2015 <dbl>, 2016 <dbl>,
## # 2017 <dbl>, 2018 <dbl>, 2019 <dbl>, 2020 <dbl>Sedaj želimo te podatke spremeniti v čisto obliko. Vse stolpce, ki prikazujejo različne vrednosti spremenljivke leto, moramo zapisati v 1 stolpec. Uporabimo funkcijo pivot_longer(), ki prejme argumente:
data. Katere podatke želimo spremeniti.cols. V katerih stolpcih imamo vrednosti spremenljivke, ki jo želimo shraniti v 1 stolpec.
df %>% pivot_longer(cols = `2007`:`2020`)## # A tibble: 5,936 x 4
## OBČINE TIP.STAVBE name value
## <chr> <chr> <chr> <dbl>
## 1 Ajdovščina Stanovanjske stavbe 2007 52
## 2 Ajdovščina Stanovanjske stavbe 2008 55
## 3 Ajdovščina Stanovanjske stavbe 2009 45
## 4 Ajdovščina Stanovanjske stavbe 2010 33
## 5 Ajdovščina Stanovanjske stavbe 2011 52
## 6 Ajdovščina Stanovanjske stavbe 2012 40
## 7 Ajdovščina Stanovanjske stavbe 2013 29
## 8 Ajdovščina Stanovanjske stavbe 2014 30
## 9 Ajdovščina Stanovanjske stavbe 2015 38
## 10 Ajdovščina Stanovanjske stavbe 2016 31
## # ... with 5,926 more rowsSedaj imamo leta shranjena v stolpcu, prav tako pa vrednosti. Stolpca sta dobila privzeti meni name in value. Funkcija pivot_longer() pa lahko prejme še več opcijskih argumentov, za nas bosta najbolj pomembna 2:
names_to. Ime stolpca, v katerega bomo shranili spremenljivko.value_to. Ime stolpca, v katerega bomo shranili vrednosti.
Uporabimo sedaj še ta 2 parametra:
df_longer <- df %>% pivot_longer(cols = `2007`:`2020`,
names_to = "Leto",
values_to = "Število")
df_longer## # A tibble: 5,936 x 4
## OBČINE TIP.STAVBE Leto Število
## <chr> <chr> <chr> <dbl>
## 1 Ajdovščina Stanovanjske stavbe 2007 52
## 2 Ajdovščina Stanovanjske stavbe 2008 55
## 3 Ajdovščina Stanovanjske stavbe 2009 45
## 4 Ajdovščina Stanovanjske stavbe 2010 33
## 5 Ajdovščina Stanovanjske stavbe 2011 52
## 6 Ajdovščina Stanovanjske stavbe 2012 40
## 7 Ajdovščina Stanovanjske stavbe 2013 29
## 8 Ajdovščina Stanovanjske stavbe 2014 30
## 9 Ajdovščina Stanovanjske stavbe 2015 38
## 10 Ajdovščina Stanovanjske stavbe 2016 31
## # ... with 5,926 more rows2.4 pivot_wider(): pretvorba v širšo obliko
Običajno bo ta transformacija naredila podatke nečiste, vendar s tem ni nič narobe, saj imajo tudi takšni podatki svoje prednosti:
- Podatki v širši obliki so človeku lažje berljivi.
- Nekatera podjetja in področja imajo razvite standarde, v katerih potrebujemo podatke v širši obliki.
- Nekatere metode, predvsem gre tukaj za metode strojnega učenja, delujejo bolje ali izključno s podatki v širši obliki.
- Če želimo podatke pretvoriti v matriko.
Za pretvorbo podatkov v širšo obliko uporabimo funkcijo pivot_wider(), ki prejme dva argumenta:
names_from. Ime stolpca, katerga želimo raztegniti v širšo obliko.values_from. Ime stolpca, v katerem so shranjene vrednosti.
Pretvorimo sedaj df_longer v širšo obliko glede na stolpec TIP.STAVBE.
df_wider <- df_longer %>%
pivot_wider(names_from = TIP.STAVBE, values_from = Število)
df_wider[1:14, ]## # A tibble: 14 x 4
## OBČINE Leto `Stanovanjske stavbe` `Nestanovanjske stavbe`
## <chr> <chr> <dbl> <dbl>
## 1 Ajdovščina 2007 52 19
## 2 Ajdovščina 2008 55 9
## 3 Ajdovščina 2009 45 22
## 4 Ajdovščina 2010 33 15
## 5 Ajdovščina 2011 52 27
## 6 Ajdovščina 2012 40 11
## 7 Ajdovščina 2013 29 23
## 8 Ajdovščina 2014 30 11
## 9 Ajdovščina 2015 38 49
## 10 Ajdovščina 2016 31 66
## 11 Ajdovščina 2017 33 60
## 12 Ajdovščina 2018 42 36
## 13 Ajdovščina 2019 38 39
## 14 Ajdovščina 2020 42 46S takšnim prikazom lahko relativno hitro opazimo določene trende. Na primer v Ajdovščini se je gradilo veliko več stanovanjskih stavb med leti 2007 in 2014, leta 2015 pa se je očitno začelo graditi več nestanovanjskih stavb, kar bi lahko nakazovalo na gospodarsko rast tega mesta. Za človeka je torej tak prikaz boljši. Vsekakor pa bi v tem primeru raje uporabili vizualizacijo.
2.5 separate() in unite(): deljenje in združevanje stolpcev
V uvodu tega poglavja smo prikazali podatke, kjer sta bili dve spremenljivki shranjeni v enem stolpcu. Poglejmo si te podatke še enkrat:
df <- read_csv2("./data-raw/SLO-gradbena-dovoljenja-messy2.csv",
locale = readr::locale(encoding = "cp1250"))
df## # A tibble: 5,936 x 3
## OBČINA_TIP Leto Število.gradbenih.dovoljenj
## <chr> <dbl> <dbl>
## 1 Ajdovščina_Stanovanjske stavbe 2007 52
## 2 Ajdovščina_Stanovanjske stavbe 2008 55
## 3 Ajdovščina_Stanovanjske stavbe 2009 45
## 4 Ajdovščina_Stanovanjske stavbe 2010 33
## 5 Ajdovščina_Stanovanjske stavbe 2011 52
## 6 Ajdovščina_Stanovanjske stavbe 2012 40
## 7 Ajdovščina_Stanovanjske stavbe 2013 29
## 8 Ajdovščina_Stanovanjske stavbe 2014 30
## 9 Ajdovščina_Stanovanjske stavbe 2015 38
## 10 Ajdovščina_Stanovanjske stavbe 2016 31
## # ... with 5,926 more rowsVčasih se srečamo celo z dvema vrednostima v istem stolpcu. Da ločimo ti spremenljivki na dva stolpca uporabimo funkcijo separate():
separate(<podatki>, col = <ime-stolpca>, into = <ime-novih-stolpcev>, sep = <znak-ki-locuje>)Uporabimo sedaj to funkcijo da pretvorimo df v čisto obliko:
df_tidy <- df %>%
separate(col = "OBČINA_TIP", into = c("OBČINA", "TIP"), sep = "_")
df_tidy## # A tibble: 5,936 x 4
## OBČINA TIP Leto Število.gradbenih.dovoljenj
## <chr> <chr> <dbl> <dbl>
## 1 Ajdovščina Stanovanjske stavbe 2007 52
## 2 Ajdovščina Stanovanjske stavbe 2008 55
## 3 Ajdovščina Stanovanjske stavbe 2009 45
## 4 Ajdovščina Stanovanjske stavbe 2010 33
## 5 Ajdovščina Stanovanjske stavbe 2011 52
## 6 Ajdovščina Stanovanjske stavbe 2012 40
## 7 Ajdovščina Stanovanjske stavbe 2013 29
## 8 Ajdovščina Stanovanjske stavbe 2014 30
## 9 Ajdovščina Stanovanjske stavbe 2015 38
## 10 Ajdovščina Stanovanjske stavbe 2016 31
## # ... with 5,926 more rowsObstaja pa tudi obratna operacija unite(), ki združi dva stolpca:
unite(<podatki>, <stolpec1>, <stolpec2>, ..., sep = <znak-ki-locuje>)Pri tem tri pikice prestavljajo morebitne preostale stolpce, saj jih lahko združimo več.
Za primer si poglejmo, kako bi v eno spremenljivko shranili podatke o številu stanovanjskih in nestanovanjskih gradbenih dovoljenj. Najprej pretvorimo podatke v širšo obliko glede na tip, potem pa ta nova stolpca združimo s funkcijo unite().
df_wider <- df_tidy %>%
pivot_wider(names_from = TIP, values_from = Število.gradbenih.dovoljenj) %>%
unite("Stanovanjske/Nestanovanjske",
"Stanovanjske stavbe",
"Nestanovanjske stavbe",
sep = "/")
df_wider## # A tibble: 2,968 x 3
## OBČINA Leto `Stanovanjske/Nestanovanjske`
## <chr> <dbl> <chr>
## 1 Ajdovščina 2007 52/19
## 2 Ajdovščina 2008 55/9
## 3 Ajdovščina 2009 45/22
## 4 Ajdovščina 2010 33/15
## 5 Ajdovščina 2011 52/27
## 6 Ajdovščina 2012 40/11
## 7 Ajdovščina 2013 29/23
## 8 Ajdovščina 2014 30/11
## 9 Ajdovščina 2015 38/49
## 10 Ajdovščina 2016 31/66
## # ... with 2,958 more rows2.6 Relacijske zbirke podatkov
Pogosto se pri analizi podatkov srečamo z razpredelnicami, ki so med seboj logično povezane. Nekaj primerov:
- V spletni trgovini lahko hranimo podatke v 3 razpredelnicah o produktih, kupcih in nakupih. Razpredelnice so med seboj povezane, na primer razpredelnica o nakupih vsebuje ID kupca in produkta.
- Baze podatkov o filmih, kot je IMDB, imajo na primer podatke o filmih, ocenjevalcih, igralcih in ocenah. Filmi povezujejo vse preostale razpredelnice.
- Biološke podatkovne zbirke lahko imajo razpredelnice atomov, molekul in vezi.
- Pri železniškem omrežju imamo razpredelnice z vlaki, vagoni, železniškimi postajami, prihodi in odhodi.
- Pri nogometu imamo razpredelnice z igralci, klubi in odigranimi tekmami.
Takšnim podatkovnim zbirkam pravimo relacijske zbirke podatkov, saj so poleg podatkov v razpredelnicah pomembne tudi relacije oziroma povezave med razpredelnicami. Zaenkrat smo se naučili, kako urejati podatke v eni razpredelnici. Če želimo analizirati relacijske podatke, moramo znati upoštevati tudi povezave med njimi in jih ustrezno združevati. V tem poglavju bomo predelali operacije, ki nam to omogočajo. Morda ste se že srečali z jezikom SQL, ki se običajno uporablja za urejanje podatkov v sistemih za upravljanje relacijskih podatkovnih baz (ang. relational database management systems, RDBMS). Paket dplyr ima podobno sintakso kot SQL, vendar pa ni popolnoma enaka. Je tudi enostavnejši za uporabo pri analizi podatkov, saj je ustvarjen prav s tem namenom.
2.7 Primer: Bančni podatki
V tem poglavju bomo delali s podatki češke banke (https://data.world/lpetrocelli/czech-financial-dataset-real-anonymized-transactions, https://relational.fit.cvut.cz/dataset/Financial). Gre za realno anonimizirano podatkovno zbirko, ki je bila uporabljena v izzivu PKDD’99 Discovery Challenge (https://sorry.vse.cz/~berka/challenge/pkdd1999/berka.htm). Cilj izziva je bil odkriti dobre in slabe kliente z namenom izboljšanja ponudbe. Mi bomo te podatke uporabili za ilustracijo operacij na relacijski zbirki podatkov.
V mapi data_raw/financial se nahaja 5 razpredelnic v csv formatu: account.csv, client.csv, disp.csv, loan.csv in transaction-smaller.csv. Izvirni podatki vsebujejo še nekaj razpredelnic, vendar jih bomo z namenom učinkovitega prikaza izpustili. Prav tako smo pri razpredelnici transaction.csv naključno izbrali 20000 vrstic, saj originalna datoteka vsebuje preko milijon vrstic, kar bi upočasnilo izvajanje ukazov in zasedlo veliko prostora na repozitoriju. V kolikor želite raziskati celotno zbirko, predlagamo, da si podatke prenesete iz vira. Poglejmo si sedaj vsako izmed razpredelnic.
Razpredelnica account vsebuje podatke o računih na banki.
account <- read_csv2("./data-raw/financial/account.csv")
account## # A tibble: 4,500 x 4
## account_id district_id frequency date
## <dbl> <dbl> <chr> <date>
## 1 1 18 monthly payment 1995-03-24
## 2 2 1 monthly payment 1993-02-26
## 3 3 5 monthly payment 1997-07-07
## 4 4 12 monthly payment 1996-02-21
## 5 5 15 monthly payment 1997-05-30
## 6 6 51 monthly payment 1994-09-27
## 7 7 60 monthly payment 1996-11-24
## 8 8 57 monthly payment 1995-09-21
## 9 9 70 monthly payment 1993-01-27
## 10 10 54 monthly payment 1996-08-28
## # ... with 4,490 more rowsRazpredelnica client vsebuje podatke o strankah.
client <- read_csv2("./data-raw/financial/client.csv")
client## # A tibble: 5,369 x 4
## client_id gender birth_date district_id
## <dbl> <chr> <date> <dbl>
## 1 1 F 1970-12-13 18
## 2 2 M 1945-02-04 1
## 3 3 F 1940-10-09 1
## 4 4 M 1956-12-01 5
## 5 5 F 1960-07-03 5
## 6 6 M 1919-09-22 12
## 7 7 M 1929-01-25 15
## 8 8 F 1938-02-21 51
## 9 9 M 1935-10-16 60
## 10 10 M 1943-05-01 57
## # ... with 5,359 more rowsRazpredelnica disp poveže podatke o osebah in računih, torej, katere osebe imajo pravico opravljati s katerimi računi.
disp <- read_csv2("./data-raw/financial/disp.csv")
disp## # A tibble: 5,369 x 4
## disp_id client_id account_id type
## <dbl> <dbl> <dbl> <chr>
## 1 1 1 1 OWNER
## 2 2 2 2 OWNER
## 3 3 3 2 DISPONENT
## 4 4 4 3 OWNER
## 5 5 5 3 DISPONENT
## 6 6 6 4 OWNER
## 7 7 7 5 OWNER
## 8 8 8 6 OWNER
## 9 9 9 7 OWNER
## 10 10 10 8 OWNER
## # ... with 5,359 more rowsRazpredelnica loan vsebuje podatke o posojilih.
loan <- read_csv2("./data-raw/financial/loan.csv")
loan## # A tibble: 682 x 7
## loan_id account_id date amount duration payments status
## <dbl> <dbl> <date> <dbl> <dbl> <dbl> <chr>
## 1 4959 2 1994-01-05 80952 24 3373 A
## 2 4961 19 1996-04-29 30276 12 2523 B
## 3 4962 25 1997-12-08 30276 12 2523 A
## 4 4967 37 1998-10-14 318480 60 5308 D
## 5 4968 38 1998-04-19 110736 48 2307 C
## 6 4973 67 1996-05-02 165960 24 6915 A
## 7 4986 97 1997-08-10 102876 12 8573 A
## 8 4988 103 1997-12-06 265320 36 7370 D
## 9 4989 105 1998-12-05 352704 48 7348 C
## 10 4990 110 1997-09-08 162576 36 4516 C
## # ... with 672 more rowsRazpredelnica trans vsebuje podatke o transakcijah.
trans <- read_csv2("./data-raw/financial/transaction-smaller.csv")
trans## # A tibble: 20,000 x 10
## trans_id account_id date type operation amount balance k_symbol bank
## <dbl> <dbl> <date> <chr> <chr> <dbl> <dbl> <chr> <chr>
## 1 736882 2517 1997-07-17 CHOICE CHOICE 21992 22279 <NA> <NA>
## 2 201830 686 1997-05-08 INCOME DEPOSIT 10533 18473 <NA> <NA>
## 3 3158278 10478 1998-01-29 EXPEN~ CHOICE 2100 8821 <NA> <NA>
## 4 41116 135 1994-05-09 EXPEN~ CHOICE 2900 21513 <NA> <NA>
## 5 1046207 3578 1996-09-08 EXPEN~ TRANSFER~ 4051 51755 SIPO KL
## 6 875501 2982 1997-04-30 EXPEN~ CHOICE 12100 41859 <NA> <NA>
## 7 893918 3047 1996-11-30 EXPEN~ CHOICE 15 24788 SERVICES <NA>
## 8 3442751 1543 1998-07-31 INCOME <NA> 71 17153 UROK <NA>
## 9 462371 1571 1998-08-25 EXPEN~ CHOICE 2760 25770 <NA> <NA>
## 10 1028586 3513 1993-10-12 EXPEN~ TRANSFER~ 4507 31227 SIPO KL
## # ... with 19,990 more rows, and 1 more variable: account <dbl>Imamo 5 razpredelnice, vse pa so med seboj povezane. Razpredelnici account in client sta povezani preko razpredelnice disp. Razpredelnici loan in transsta povezani z razpredelnico account preko spremenljivke account_id. To strukturo najbolje prikažemo z relacijskim diagramom.
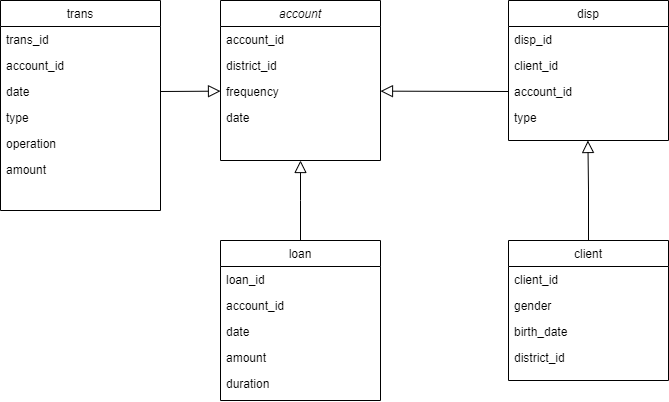
Relacijski diagram
2.8 Ključi
Spremenljivkam, ki povezujejo razpredelnice, pravimo ključi. Te spremenljivke (ali zbirke spremenljivk) edinstveno definirajo podatke. Lahko gre za eno spremenljivko, kot je na primer account_id v razpredelnici account. Lahko pa obstaja več spremenljivk, ki definirajo en podatek. Na primer, če imamo razpredelnico s temperaturami za vsak dan in uro. Potem ni nujno, da ima vsaka vrstica svoj ID, lahko pa jih edinstveno ločimo na podlagi dveh spremenljivk – dneva in ure. V tem primeru gre torej za ključ, ki je sestavljen iz dveh spremenljivk.
Poznamo dva glavna tipa ključev:
- Primarni ključ. Ta ključ edinstveno definira podatek v razpredelnici. Na primer,
trans_idv razpredelnicitrans. V urejenih podatkih ima vsaka tabela svoj primarni ključ. - Tuj ključ. To je ključ v razpredelnici, ki je primarni ključ v eni od preostalih razpredelnic. Na primer,
account_idv razpredelnicitrans. Vrednosti tujih ključev se lahko podvajajo. Na primer, več transakcij lahko ima isto vrednost tujega ključa zaaccount_id, saj se na enem bančnem računu izvede več transakcij.
V kolikor razpredelnica nima primarnega ključa, lahko ustvarimo t. i. nadomestni ključ, ki igra vlogo primarnega ključa. To lahko naredimo na primer tako, da vsaki vrstici priredimo njeno zaporedno vrednost v razpredelnici. Na primer mutate(row_number()).
Primarni in tuj ključ skupaj tvorita relacijo med razpredelnicama. Na primer account_id predstavlja relacijo med razpredelnicama trans in account. Relacije so lahko ena-proti-ena (ena država ima enega predsednika in ena oseba je lahko predsednik samo ene države), ena-proti-mnogo (en igralec lahko igra za en klub, ampak en klub ima več igralcev) ali mnogo-proti-mnogo (en avtor lahko napiše več knjig in ena knjiga je lahko napisana s strani večih avtorjev).
Kadar imamo opravka z relacijskimi podatki, je smiselno preveriti, ali je primarni ključ res edinstven za vsako razpredelnico.
df_list <- list(account, client, disp, trans, loan)
id_vec <- c("account_id", "client_id", "disp_id", "trans_id", "loan_id")
for (i in 1:length(df_list)) {
tmp <- df_list[[i]] %>%
group_by(.data[[id_vec[i]]]) %>%
summarise(n = n()) %>%
filter(n > 1)
print(tmp)
}## # A tibble: 0 x 2
## # ... with 2 variables: account_id <dbl>, n <int>
## # A tibble: 0 x 2
## # ... with 2 variables: client_id <dbl>, n <int>
## # A tibble: 0 x 2
## # ... with 2 variables: disp_id <dbl>, n <int>
## # A tibble: 0 x 2
## # ... with 2 variables: trans_id <dbl>, n <int>
## # A tibble: 0 x 2
## # ... with 2 variables: loan_id <dbl>, n <int>V prejšnjem klicu kode se pojavi nova sintaksa, in sicer .data[[id_vec[i]]]. Funkcija group_by() uporablja t. i. tidyselect, s katerim izbiramo stolpce brez da bi jih dali v narekovaje. To pa predstavlja težavo, kadar so imena stolpcev shranjena v neki spremenljivki, kot v tem primeru. Tidyverse je ustvarjen na načelu, da olajša bolj pogoste operacije (na primer, enostavno uporaba group_by() pri urejanju posamezne razpredelnice), za ceno težje izvedbe manj pogostih operacij (na primer, uporaba group_by() v zanki for). Veliko večino urejanja podatkov bomo lahko z uporabo tidyverse naredili brez uporabe zank ali naprednih lastnih funkcij. V kolikor se boste lotili bolj programerskega pristopa, pa predlagamo, da si preberete navodila za programiranje z dplyr, ki jih dobite tako, da v konzoli kličete vignette('programming'). Na tej delavnici ne bomo predstavili podrobnosti teh pristopov. Zaenkrat je dovolj, da poznamo samo zgornji klic. Torej, če imamo imena stolpcev shranjena v neki spremenljivki, potem moramo znotraj tidyselecta uporabiti .data[[<spremenljivka-z-imeni-stolpcev>]].
2.9 Združevanja
Kadar imamo opravka z večimi razpredelnicami potrebujemo orodja, s katerimi lahko posamezne pare razpredelnic združimo. Vešči uporabniki R morda že poznajo funkcijo merge, ki je del osnovne različice R in je namenjena splošnemu združevanju razpredelnic. Seveda pa tidyverse premore svoje različice podobnih funkcij, ki premorejo enake lastnosti kot preostale funkcije v tej zbirki – prejmejo in vrnejo podatke v enakem formatu in sicer tibblu. Poleg tega so funkcije iz paketa dplyr tudi hitrejše od merge, kar ima pomembno vlogo, kadar imamo opravka z nekoliko večjimi podatkovnimi množicami.
Združevanja podatkovnih razpredelnic lahko ločimo na 3 sklope:
- Mutirajoča združevanja (ang. mutating joins). Dodajo nove stolpce k razpredelnici iz ujemajočih vrstic druge razpredelnice.
- Filtrirajoča združevanja (ang. filtering joins). Izberejo vrstice ene razpredenice glede na to, ali se te ujemajo z vrsticami v drugi razpredelnici.
- Operacije nad množicami. Operirajo nad vrsticami, kot da so ti deli množice.
2.9.1 Mutirajoča združevanja
Mutirajoča združevanja so pogosta operacija pri delu z relacijskimi podatki. Te operacije združijo dve (ali več) razpredelnici glede na vrednosti stolpcev. Obstajajo 4 takšne operacije:
left_join(). Ohrani vse vrstice prve (leve) razpredelnice in poveže ustrezne vrstice iz druge razpredelnice s temi vrsticami.right_join(). Ohrani vse vrstice druge (desne) razpredelnice in poveže ustrezne vrstice iz prve rapredelnice s temi vrsticami.full_join(). Ohrani vse vrstice obeh razpredelnic.inner_join(). Ohrani samo tiste vrstice, ki se pojavijo v obeh razpredelnicah.
Prvi trije so tako imenovani zunanji stiki (outer join), saj uporabijo vrstice, ki se pojavijo vsaj v eni razpredelnici. Za lažje razumevanje bomo najprej prikazali uporabo stikov na podatkih, ki jih bomo ustvarili sami. Sintaksa pri vseh združevanjih je:
left_join(<razpredelnica1>, <razpredelnica2>)Ustvarimo dva tibbla:
df1 <- tibble(
id = c("id1", "id2", "id3", "id4"),
x = c(4, 6, 1, 2)
)
df2 <- tibble(
id = c("id1", "id3", "id4", "id5"),
y = c(20, 52, 11, 21)
)
df1## # A tibble: 4 x 2
## id x
## <chr> <dbl>
## 1 id1 4
## 2 id2 6
## 3 id3 1
## 4 id4 2df2## # A tibble: 4 x 2
## id y
## <chr> <dbl>
## 1 id1 20
## 2 id3 52
## 3 id4 11
## 4 id5 21left_join()obdrži tibbledf1takšen kot je in mu pripne stolpecyiz tibbladf2, kjer so vrednosti spremenljivkeidenake. Za tiste vrsticedf1, ki nimajo ustreznegaidvdf2se vrednosti v spremenljivkiynastavijo naNA.
left_join(df1, df2)## # A tibble: 4 x 3
## id x y
## <chr> <dbl> <dbl>
## 1 id1 4 20
## 2 id2 6 NA
## 3 id3 1 52
## 4 id4 2 11right_join()obdrži tibbledf2takšen kot je in mu pripne stolpecxiz tibbladf1, kjer so vrednosti spremenljivkeidenake. Za tiste vrsticedf2, ki nimajo ustreznegaidvdf1, se vrednosti v spremenljivkiynastavijo naNA.
right_join(df1, df2)## # A tibble: 4 x 3
## id x y
## <chr> <dbl> <dbl>
## 1 id1 4 20
## 2 id3 1 52
## 3 id4 2 11
## 4 id5 NA 21inner_join()obdrži samo tiste podatke, kjer seidnahaja v obeh razpredelnicah (torej 1, 3 in 4). Vse preostale vrstice zavrže.
inner_join(df1, df2)## # A tibble: 3 x 3
## id x y
## <chr> <dbl> <dbl>
## 1 id1 4 20
## 2 id3 1 52
## 3 id4 2 11full_join()obdrži vse podatke izdf1indf2. Kjer ni ustreznegaidv nasprotni razpredelnici se vrednosti nastavijo naNA.
full_join(df1, df2)## # A tibble: 5 x 3
## id x y
## <chr> <dbl> <dbl>
## 1 id1 4 20
## 2 id2 6 NA
## 3 id3 1 52
## 4 id4 2 11
## 5 id5 NA 21Najbolj pogosto bomo uporabljali left_join(), kadar bo cilj obdržati originalno razpredelnico, kot je, ali inner_join(), kadar bomo želeli podatke brez manjkajočih vrednosti. Stik right_join() je samo drugače usmerjen left_join().
Do sedaj smo prikazovali, kako združimo razpredelnice glede na primarni ključ, za katerega predpostavljamo, da je unikaten. Torej vsaka vrstica ima svoj ključ, ki se v razpredelnici ne ponovi. Včasih pa razpredelnice združujemo glede na sekundarni ključ. V tem primeru se lahko zgodi, da imamo relacijo ena-proti-mnogo. Če vzamemo bančne podatke od zgoraj ima lahko en račun več skrbnikov. Kaj se zgodi v tem primeru? Kaj pa če združimo transakcije in osebe glede na račun? En račun ima lahko več transakcij in več skrbnikov. Ker pri obeh razpredelnicah uporabimo sekundarni ključ, bomo najverjetneje dobili podvojene vrednosti pri obeh. Poglejmo si sedaj na primeru podatkov, ki jih generiramo sami.
df3 <- tibble(
id1 = c("id1", "id2", "id3", "id4"),
id2 = c("id1", "id1", "id3", "id4"),
x = c(5, 6, 1, 2)
)
df4 <- tibble(
id2 = c("id1", "id2", "id3"),
y = c(20, 52, 11)
)
df5 <- tibble(
id3 = c("id1", "id2", "id3", "id4"),
id2 = c("id1", "id1", "id4", "id5"),
z = c(5, 1, 23, 5)
)
df3## # A tibble: 4 x 3
## id1 id2 x
## <chr> <chr> <dbl>
## 1 id1 id1 5
## 2 id2 id1 6
## 3 id3 id3 1
## 4 id4 id4 2df4## # A tibble: 3 x 2
## id2 y
## <chr> <dbl>
## 1 id1 20
## 2 id2 52
## 3 id3 11df5## # A tibble: 4 x 3
## id3 id2 z
## <chr> <chr> <dbl>
## 1 id1 id1 5
## 2 id2 id1 1
## 3 id3 id4 23
## 4 id4 id5 5df3 in df5 imata podvojen sekundarni ključ. Združimo sedaj df3 in df4 z uporabo inner_join().
inner_join(df3, df4)## # A tibble: 3 x 4
## id1 id2 x y
## <chr> <chr> <dbl> <dbl>
## 1 id1 id1 5 20
## 2 id2 id1 6 20
## 3 id3 id3 1 11Ključ torej ostane podvojen. Kaj pa se zgodi, če imata obe razpredelnici podvojene ključe? V tem primeru dobimo kartezični produkt vseh podvojenih vrednosti:
inner_join(df3, df5)## # A tibble: 5 x 5
## id1 id2 x id3 z
## <chr> <chr> <dbl> <chr> <dbl>
## 1 id1 id1 5 id1 5
## 2 id1 id1 5 id2 1
## 3 id2 id1 6 id1 5
## 4 id2 id1 6 id2 1
## 5 id4 id4 2 id3 23df3 in df5 imata podvojeno vrednost ključa id1. Torej dobimo vse kombinacije preostalih vrednosti (5, 5), (5, 1), (6, 5) in (6, 1).
2.9.2 Argument by
Združevanja, ki smo jih spoznali, privzeto združijo razpredelnici glede na vrednosti v vseh stolpcih, ki imajo enaka imena – tamu pravimo tudi naravno združevanje (ang. natural join). Lahko pa tudi sami določimo, po katerih stolpcih želimo združiti podatke. To naredimo tako, da pri združevanjih uporabimo argument by. Sintaksa združevanj je potem:
inner_join(<razpredelnica1>, <razpredelnica2>, by = <vektor-imen-stolpcev>)inner_join() dveh razpredelnic bi potem zapisali kot:
inner_join(df3, df4, by = "id2")## # A tibble: 3 x 4
## id1 id2 x y
## <chr> <chr> <dbl> <dbl>
## 1 id1 id1 5 20
## 2 id2 id1 6 20
## 3 id3 id3 1 11Ta primer služi samo kot ilustracija in je uporaba by nepotrebna. Seveda pa se pri realnih podatkih velikokrat srečamo s stanjem, kjer ta argument potrebujemo. Prav tako je koda s parametrom by bolj robustna, saj sami definiramo, glede na katere stolpce naj se razpredelnice združujejo in ne more priti do kakšnih napak pri ponovljivosti.
Razpredelnici lahko združimo tudi po stolpcih, ki nimajo istega imena. Ni nenavadno, da imamo dve razpredelnici z enakimi spremenljivkami, ki pa so poimenovane drugače. Če bi želeli taki razpredelnici združiti glede na to spremenljivko, potem bi jo morali načeloma v eni razpredelnici preimenovati. S paketom dplyr pa lahko to naredimo tudi drugače. Združimo sedaj df3 in df5 glede na stolpca x in z ter skupni stolpec id2.
inner_join(df3, df5, by = c("x" = "z", "id2"))## # A tibble: 1 x 4
## id1 id2 x id3
## <chr> <chr> <dbl> <chr>
## 1 id1 id1 5 id12.9.3 Filtrirajoča združevanja
Pri filtrirajočih združevanjih ne gre toliko za združevanja, kolikor gre za izbiro posameznih vrstic, glede na ujemanje vrednotsti stolpcev v neki drugi razpredelnici. Poznamo 2 takšni združevanji:
semi_join(). Obdrži vse vrstice v prvi razpredelnici, ki ustrezajo vrsticam v drugi razpredelnici.anti_join(). Izloči vse vrstice v prvi razpredelnici, ki ustrezajo vrsticam v drugi razpredelnici.
Poglejmo si uporabo teh združevanj na naših generiranih razpredelnicah.
df1## # A tibble: 4 x 2
## id x
## <chr> <dbl>
## 1 id1 4
## 2 id2 6
## 3 id3 1
## 4 id4 2df2## # A tibble: 4 x 2
## id y
## <chr> <dbl>
## 1 id1 20
## 2 id3 52
## 3 id4 11
## 4 id5 21semi_join(df1, df2)## # A tibble: 3 x 2
## id x
## <chr> <dbl>
## 1 id1 4
## 2 id3 1
## 3 id4 2semi_join() je torej izločil vrstico z id2, saj se ta ne pojavi v df2.
anti_join(df1, df2)## # A tibble: 1 x 2
## id x
## <chr> <dbl>
## 1 id2 6semi_join() je torej izločil vse vrstice, ki se pojavijo tudi v df2. Ostane torej samo vrstica z id2.
2.9.4 Združevanja na realnih podatkih
Sedaj, ko smo spoznali glavne lastnosti različnih združevanj na primerih, ki so nam omogočali lažjo predstavo, pa se posvetimo realnim podatkom, ki smo jih predstavili v začetku tega poglavja. Imamo torej podatke o bančnih računih, transakcijah, posojilih, skrbnikih računov in povezovalno razpredelnico med računi in skrbniki. Lotimo se sedaj relativno enostavne analize, kjer bomo naredili sledeče:
- Ustvarili novo razpredelnico, kjer bomo imeli podatke o vseh bančnih računih in o lastnikih teh računov. Lastnik računa je lahko samo en, medtem ko je skrbnikov lahko več.
- Filtrirali razpredelnico iz točke 1), v kateri bodo samo tisti, ki imajo posojila nad 100000 kron.
- Ustvarili novo razpredelnico klientov, kjer bomo imeli podatke o klientih in posojilih in bodo zajeti samo klienti s posojili.
- Izračunali kateri klienti, ki imajo posojilo, imajo tudi največ transakcij.
Za vsakega izmed teh korakov bomo morali uporabiti eno od združevanj, ki smo jih spoznali. Na primer, v samih razpredelnicah nimamo direktne povezave med komitenti in transakcijami, tako da bomo morali zadeve nekako združiti. Podobno velja za ostale alineje.
Najprej želimo združiti razpredelnici account in client. Za to bomo potrebovali povezovalno razpredelnico disp v kateri se tudi nahaja informacija o tem, ali je klient lastnik ali samo skrbnik računa. Najprej povežemo razpredelnico account z razpredelnico disp in filtriramo glede na tip klienta:
account_disp <- left_join(account, disp) %>%
filter(type == "OWNER")
account_disp## # A tibble: 4,500 x 7
## account_id district_id frequency date disp_id client_id type
## <dbl> <dbl> <chr> <date> <dbl> <dbl> <chr>
## 1 1 18 monthly payment 1995-03-24 1 1 OWNER
## 2 2 1 monthly payment 1993-02-26 2 2 OWNER
## 3 3 5 monthly payment 1997-07-07 4 4 OWNER
## 4 4 12 monthly payment 1996-02-21 6 6 OWNER
## 5 5 15 monthly payment 1997-05-30 7 7 OWNER
## 6 6 51 monthly payment 1994-09-27 8 8 OWNER
## 7 7 60 monthly payment 1996-11-24 9 9 OWNER
## 8 8 57 monthly payment 1995-09-21 10 10 OWNER
## 9 9 70 monthly payment 1993-01-27 12 12 OWNER
## 10 10 54 monthly payment 1996-08-28 13 13 OWNER
## # ... with 4,490 more rowsSedaj lahko to novo razpredelnico povežemo z razpredelnico client.
account_client <- left_join(account_disp, client)S tem smo dobili željeno razpredelnico, v kateri imamo za vsak račun tudi informacijo o lastniku. Kot drugi korak želimo ustvariti razpredelnico, v kateri bodo samo podatki o klientih, ki imajo posojila v vrednosti več kot 100000 kron. Najprej ustvarimo razpredelnico, v kateri so samo takšna posojila, nato pa uporabimo semi_join(), ki bo iz razpredelnice account_client izbral samo vrstice, ki se bodo ujemale z vrsticami v tej novi razpredelnici posojil.
loan_100k <- loan %>%
filter(amount > 100000)
account_100k <- semi_join(account_client, loan_100k)
account_100k## # A tibble: 0 x 9
## # ... with 9 variables: account_id <dbl>, district_id <dbl>, frequency <chr>,
## # date <date>, disp_id <dbl>, client_id <dbl>, type <chr>, gender <chr>,
## # birth_date <date>Hm…dobili smo prazen tibble, čeprav obstajajo tako velika posojila. Zakaj je do tega prišlo? V obeh razpredelnicah se nahajata spremenjivki account_id in date. Ampak spremenljivka date ni ista spremenljivka, pri razpredelnici account_client predstavlja, kdaj je bil račun odprt, pri loan_100k pa predstavlja kdaj je bilo posojilo odobreno. Torej po tej spremenljivki ne smemo združevati. Uporabimo by:
account_100k <- semi_join(account_client, loan_100k, by = "account_id")
account_100k## # A tibble: 377 x 9
## account_id district_id frequency date disp_id client_id type gender
## <dbl> <dbl> <chr> <date> <dbl> <dbl> <chr> <chr>
## 1 37 20 monthly pay~ 1997-08-18 45 45 OWNER M
## 2 38 19 weekly paym~ 1997-08-08 46 46 OWNER F
## 3 67 16 monthly pay~ 1994-10-19 78 78 OWNER F
## 4 97 74 monthly pay~ 1996-05-05 116 116 OWNER M
## 5 103 44 monthly pay~ 1996-03-10 124 124 OWNER M
## 6 105 21 monthly pay~ 1997-07-10 127 127 OWNER F
## 7 110 36 monthly pay~ 1996-07-17 132 132 OWNER M
## 8 173 66 monthly pay~ 1993-11-26 210 210 OWNER M
## 9 226 70 monthly pay~ 1997-02-23 272 272 OWNER F
## 10 276 38 monthly pay~ 1997-12-08 333 333 OWNER M
## # ... with 367 more rows, and 1 more variable: birth_date <date>V naslednjem koraku želimo imeti podatke o klientih in posojilih. Najprej bomo morali združiti razpredelnici client in disp, nato pa dodati še razpredelnico loan. Ustvarimo to novo razpredelnico kar z uporabo operatorja %>%:
client_loan <- client %>%
left_join(disp) %>%
inner_join(loan, by = "account_id")
client_loan## # A tibble: 827 x 13
## client_id gender birth_date district_id disp_id account_id type loan_id
## <dbl> <chr> <date> <dbl> <dbl> <dbl> <chr> <dbl>
## 1 2 M 1945-02-04 1 2 2 OWNER 4959
## 2 3 F 1940-10-09 1 3 2 DISPONENT 4959
## 3 25 F 1939-04-23 21 25 19 OWNER 4961
## 4 31 M 1962-02-09 68 31 25 OWNER 4962
## 5 45 M 1952-08-26 20 45 37 OWNER 4967
## 6 46 F 1940-01-30 19 46 38 OWNER 4968
## 7 78 F 1944-06-13 16 78 67 OWNER 4973
## 8 116 M 1942-01-28 74 116 97 OWNER 4986
## 9 117 F 1936-09-20 74 117 97 DISPONENT 4986
## 10 124 M 1967-09-21 44 124 103 OWNER 4988
## # ... with 817 more rows, and 5 more variables: date <date>, amount <dbl>,
## # duration <dbl>, payments <dbl>, status <chr>Na koncu preverimo še, kateri klienti, ki imajo posojilo, imajo največ transakcij. Za to bomo morali najprej izračunati število transakcij na vsakem bančnem računu. Uporabimo znanje, ki smo ga pridobili na prvem predavanju:
trans_count <- trans %>%
group_by(account_id) %>%
summarise(n_trans = n())
trans_count## # A tibble: 4,205 x 2
## account_id n_trans
## <dbl> <int>
## 1 1 6
## 2 2 10
## 3 3 3
## 4 4 6
## 5 5 3
## 6 6 8
## 7 7 3
## 8 8 7
## 9 9 3
## 10 10 1
## # ... with 4,195 more rowsleft_join(client_loan, trans_count) %>%
arrange(desc(n_trans))## # A tibble: 827 x 14
## client_id gender birth_date district_id disp_id account_id type loan_id
## <dbl> <chr> <date> <dbl> <dbl> <dbl> <chr> <dbl>
## 1 11126 F 1965-01-22 1 10818 9034 OWNER 6820
## 2 6367 M 1970-04-28 44 6367 5270 OWNER 6077
## 3 7291 F 1940-12-02 77 7291 6034 OWNER 6228
## 4 7195 M 1962-09-11 50 7195 5952 OWNER 6216
## 5 4620 F 1940-11-01 54 4620 3834 OWNER 5754
## 6 4621 M 1946-02-10 54 4621 3834 DISPONENT 5754
## 7 11461 M 1974-07-08 70 11153 9307 OWNER 6895
## 8 11866 M 1937-09-02 1 11558 9640 OWNER 6960
## 9 11867 F 1934-11-19 1 11559 9640 DISPONENT 6960
## 10 13657 F 1963-05-12 59 13349 11111 OWNER 7259
## # ... with 817 more rows, and 6 more variables: date <date>, amount <dbl>,
## # duration <dbl>, payments <dbl>, status <chr>, n_trans <int>2.10 Operacije nad množicami
V tem poglavju si bomo ogledali operacije nad množicami. Te delujejo nad vektorji, prav tako pa nad data.frame oziroma nad tibbli. Poznamo 3 glavne operacije:
- Unija. Vrne vse elemente, ki se pojavijo v eni ali drugi množici.
- Presek. Vrne vse elemente, ki se pojavijo v obeh množicah.
- Razlika. Vrne vse elemente prve množice, ki se ne pojavijo v drugi množici.
Poglejmo si uporabo teh operacij nad tibbli.
df1 <- tibble(
id = c("id1", "id2"),
x = c(4, 6)
)
df2 <- tibble(
id = c("id1", "id3"),
x = c(4, 52)
)
df1## # A tibble: 2 x 2
## id x
## <chr> <dbl>
## 1 id1 4
## 2 id2 6df2## # A tibble: 2 x 2
## id x
## <chr> <dbl>
## 1 id1 4
## 2 id3 52union(df1, df2)## # A tibble: 3 x 2
## id x
## <chr> <dbl>
## 1 id1 4
## 2 id2 6
## 3 id3 52intersect(df1, df2)## # A tibble: 1 x 2
## id x
## <chr> <dbl>
## 1 id1 4setdiff(df1, df2)## # A tibble: 1 x 2
## id x
## <chr> <dbl>
## 1 id2 6setdiff(df2, df1)## # A tibble: 1 x 2
## id x
## <chr> <dbl>
## 1 id3 522.11 Ali želite izvedeti več?
Hadley Wickham je objavil znanstveni članek na temo urejenih podatkov: https://vita.had.co.nz/papers/tidy-data.pdf, ki je vsekakor vreden branja. Za več informacij o neurejenih podatkih in v katerih primerih so lahko celo bolj zaželjeni, predlagamo ta blog: https://simplystatistics.org/2016/02/17/non-tidy-data/.
2.12 Domača naloga
Spodaj imamo podatke o stroških za 4 osebe. Razpredelnica je v neurejeni obliki. Vaša naloga je, da jo pretvorite v urejeno obliko.
podatki_o_stroskih <- tibble( ime = c("Miha", "Ana", "Andrej", "Maja"), april_2019 = c(400, 200, 300, 350), maj_2019 = c(390, 250, 280, 400), april_2020 = c(410, 150, 500, 400), maj_2020 = c(300, 320, 550, 320) )Rešitev:
## # A tibble: 16 x 4 ## ime mesec leto strosek ## <chr> <chr> <chr> <dbl> ## 1 Miha april 2019 400 ## 2 Miha maj 2019 390 ## 3 Miha april 2020 410 ## 4 Miha maj 2020 300 ## 5 Ana april 2019 200 ## 6 Ana maj 2019 250 ## 7 Ana april 2020 150 ## 8 Ana maj 2020 320 ## 9 Andrej april 2019 300 ## 10 Andrej maj 2019 280 ## 11 Andrej april 2020 500 ## 12 Andrej maj 2020 550 ## 13 Maja april 2019 350 ## 14 Maja maj 2019 400 ## 15 Maja april 2020 400 ## 16 Maja maj 2020 320V mapi data-raw se nahajajo podatki o predsedniških volitvah v ZDA. Najprej izberite samo podmnožico vrstic, kjer sta kandidata Joe Biden ali Donald Trump, in izločite stolpec
party. Nato pretvorite podatke v širšo obliko, tako da bo vsak izmed kandidatov imel svoj stolpec.## # A tibble: 4,633 x 4 ## state county `Joe Biden` `Donald Trump` ## <chr> <chr> <dbl> <dbl> ## 1 Delaware Kent County 44518 40976 ## 2 Delaware New Castle County 194238 87685 ## 3 Delaware Sussex County 56657 71196 ## 4 District of Columbia District of Columbia 29509 1149 ## 5 District of Columbia Ward 2 24247 2365 ## 6 District of Columbia Ward 3 33584 2972 ## 7 District of Columbia Ward 4 35117 1467 ## 8 District of Columbia Ward 5 36585 1416 ## 9 District of Columbia Ward 6 44699 3360 ## 10 District of Columbia Ward 7 30253 885 ## # ... with 4,623 more rowsPri bančnih podatkih smo zaenkrat delali samo s petimi razpredelnicami. Celotna zbirka je nekoliko večja, saj vsebuje še 3 razpredelnice. V mapi data-raw/financial-hw/ se nahajajo še preostale razpredelnice. Pri nalogi bomo uporabili razpredelnico district, ki vsebuje podatke o okrajih. Vsekakor pa se lahko za lastno vajo poigrate še s preostalima dvema. Vaše naloge so:
Preberite podatke o okrajih v R.
Ugotovite, kaj je primarni ključ te razpredelnice.
Ustrezno dopolnite entitetni diagram. To lahko naredite ročno, v kolikor pa se želite naučiti narediti bolj profesionalne diagrame pa predlagamo spletno orodje https://app.diagrams.net/. V mapi support-files se nahaja naš diagram. Tega lahko enostavno naložite v to orodje in ga dopolnite.
Poiščite 3 pokrajine (A3) z največjo povprečno vrednostjo posojil.
## # A tibble: 3 x 2 ## A3 mean_loan ## <chr> <dbl> ## 1 east Bohemia 165997. ## 2 south Bohemia 156236. ## 3 central Bohemia 155392.
- Težka naloga. Namestite paket nycflights13. Gre za relacijsko podatkovno zbirko o letih iz New Yorka v letu 2013. Naložite podatke z
library(nycflights13). Uporabljali bomo štiri razpredelnice: flights, weather, airlines in planes. Vaša naloga je:
Poizkusite najti primarni ključ za razpredelnico
flights. Ali gre za primarni ključ lahko preverite tako, da preverite ali ta ključ unikatno določa vrstico v podatkih, torej da preštejete podatke, grupirane glede na ta ključ. Ključ je lahko sestavljen tudi iz večih spremenljivk. Na prvi pogled bi rekli, da je primarni ključ številka leta, ampak temu ni tako (preverimo s štetjem). Ali je morda kakšna druga kombinacija spremenljivk? Lahko da razpredelnica nima primarnega ključa. V tem primeru določite nadomestni ključ tako, da dodate stolpec ID zmutate(ID = row_number()).Ugotovite, kaj so primarni in kaj tuji ključi preostalih razpredelnic. Pri nekaterih razpredelnicah v tej zbirki bomo imeli sestavljene ključe, torej bodo ključi sestavljeni iz večih stolpcev. Namig: Pri vremenu je manjša napaka v podatkih in se tudi primarni ključ ponovi v zanemarljivem številu primerov. Vsekakor so napake v realnih podatkih pričakovane in moramo na to biti pozorni!
Narišite relacijski diagram.
Ustvarite novo razpredelnico tako da razpredelnici
flightsdodate podrobnosti o lastnostih letal za vsak let.## # A tibble: 336,776 x 28 ## ID year.x month day dep_time sched_dep_time dep_delay arr_time ## <int> <int> <int> <int> <int> <int> <dbl> <int> ## 1 1 2013 1 1 517 515 2 830 ## 2 2 2013 1 1 533 529 4 850 ## 3 3 2013 1 1 542 540 2 923 ## 4 4 2013 1 1 544 545 -1 1004 ## 5 5 2013 1 1 554 600 -6 812 ## 6 6 2013 1 1 554 558 -4 740 ## 7 7 2013 1 1 555 600 -5 913 ## 8 8 2013 1 1 557 600 -3 709 ## 9 9 2013 1 1 557 600 -3 838 ## 10 10 2013 1 1 558 600 -2 753 ## # ... with 336,766 more rows, and 20 more variables: sched_arr_time <int>, ## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, ## # dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, ## # time_hour <dttm>, year.y <int>, type <chr>, manufacturer <chr>, ## # model <chr>, engines <int>, seats <int>, speed <int>, engine <chr>Ustvarite novo razpredelnico tako da razpredelnici
flightsdodate podrobnosti o vremenu na letališču vsak let.## # A tibble: 336,776 x 30 ## ID year month day dep_time sched_dep_time dep_delay arr_time ## <int> <int> <int> <int> <int> <int> <dbl> <int> ## 1 1 2013 1 1 517 515 2 830 ## 2 2 2013 1 1 533 529 4 850 ## 3 3 2013 1 1 542 540 2 923 ## 4 4 2013 1 1 544 545 -1 1004 ## 5 5 2013 1 1 554 600 -6 812 ## 6 6 2013 1 1 554 558 -4 740 ## 7 7 2013 1 1 555 600 -5 913 ## 8 8 2013 1 1 557 600 -3 709 ## 9 9 2013 1 1 557 600 -3 838 ## 10 10 2013 1 1 558 600 -2 753 ## # ... with 336,766 more rows, and 22 more variables: sched_arr_time <int>, ## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, ## # dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, ## # time_hour.x <dttm>, temp <dbl>, dewp <dbl>, humid <dbl>, wind_dir <dbl>, ## # wind_speed <dbl>, wind_gust <dbl>, precip <dbl>, pressure <dbl>, ## # visib <dbl>, time_hour.y <dttm>Poiščite vsa letala z 2 motorjema, ki so v New York priletela 5. aprila iz letališča Chicago Ohare Intl.
## # A tibble: 35 x 35 ## ID year.x month day dep_time sched_dep_time dep_delay arr_time ## <int> <int> <int> <int> <int> <int> <dbl> <int> ## 1 169022 2013 4 5 545 600 -15 710 ## 2 169051 2013 4 5 604 610 -6 739 ## 3 169062 2013 4 5 624 630 -6 755 ## 4 169086 2013 4 5 636 630 6 814 ## 5 169100 2013 4 5 653 700 -7 827 ## 6 169114 2013 4 5 659 700 -1 823 ## 7 169125 2013 4 5 720 725 -5 851 ## 8 169159 2013 4 5 752 759 -7 920 ## 9 169183 2013 4 5 810 815 -5 933 ## 10 169201 2013 4 5 823 830 -7 957 ## # ... with 25 more rows, and 27 more variables: sched_arr_time <int>, ## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, ## # dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, ## # time_hour <dttm>, year.y <int>, type <chr>, manufacturer <chr>, ## # model <chr>, engines <int>, seats <int>, speed <int>, engine <chr>, ## # name <chr>, lat <dbl>, lon <dbl>, alt <dbl>, tz <dbl>, dst <chr>, ## # tzone <chr>
Zelo težka naloga. V mapi data-raw se nahajajo podatki o kreditnih karticah v Tajvanu default of credit card clients.xlsx. Pridobili smo jih iz UCI Machine Learning repozitorija (Dua and Graff 2017). Podatki so bili uporabljeni v znanstveni raziskavi (Yeh and Lien 2009), kjer so napovedovali verjetnosti neplačil v odvisnosti od preteklih transakcij na kartici in podatkov o lastnikih. Podatki so v xlsx datoteki. Bodite pozorni, da je prva vrstica datoteke nepomembna in se glava začne komaj v drugi vrstici. Trenutno so podatki v obliki, v kateri so zelo primerni kot vhodni podatek za kak model, na primer linearno regresijo. Vsekakor pa niso v primerni obliki za učinkotivo urejanje in hranjenje. Vaša naloga je, da podatke preberete v R in razpredelnico pretvorite v urejeno obliko.
Predlagamo, da nalogo poizkusite rešiti sami. Naloga zahteva precej razmisleka in tudi nekaj samostojne raziskave (na primer, kaj posamezni stolpci pomenijo – pomagate si lahko s spletno stranjo, iz katere smo prenesli podatke). V kolikor se vam zatakne, smo vam spodaj pripravili nekaj namigov:
Najprej je potrebno razmisliti, kaj so spremenljivke. Na primer, ali sta
PAY_1inPAY_22 spremenljivki, ali predstavljata 1 spremenljivko, ki pa je razdeljena glede na neko drugo spremenljivko?Predlagamo da začnete ukaze tako, da razpredelnico spremenite v daljšo obliko, kjer vse spremenljivke, ki se pojavijo v večih stolpcih, shranite v 1 stolpec.
V novem stolpcu so celice sestavljene iz 2 spremenljivk. Ena od teh je ID meseca. Torej moramo ta stolpec ločiti na 2 stolpca. Katero funkcijo uporabimo za to? Pri tem bo prav prišel tudi argument te funkcije
sep = -1, ki bo stolpec ločil na zadnji znak v besedi in vse preostalo (na primer, “beseda3” bo razdelil na “beseda” in “3”). -1 predstavlja pri koliko znakih od konca proti začetku naredimo ločitev besede.V enem od teh dveh preostalih stolpcev imamo še vedno shranjene 3 spremenljivke, za katere bi bilo bolje, če so v 3 stolpcih. Ustrezno pretvorite tabelo. Na tej točki smo že skoraj pri koncu.
ID mesecev žal ne sovpada z zaporednimi števili mesecev v letu. Predlagamo, da si ustvarite novo razpredelnico, ki bo mapirala ID mesecev v njihova zaporedna števila. Potem pa to razpredelnico povežete z razpredelnico, kjer hranimo podatke. Kako naredimo to? Kadar združujemo razpredelnice moramo tudi biti pozorni na to, da so stolpci, ki jih združujemo, istega tipa.
## # A tibble: 180,000 x 10 ## ID LIMIT_BAL SEX EDUCATION MARRIAGE AGE MONTH PAY PAY_AMT BILL_AMT ## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <int> <dbl> <dbl> <dbl> ## 1 1 20000 2 2 1 24 9 2 0 3913 ## 2 1 20000 2 2 1 24 8 2 689 3102 ## 3 1 20000 2 2 1 24 7 -1 0 689 ## 4 1 20000 2 2 1 24 6 -1 0 0 ## 5 1 20000 2 2 1 24 5 -2 0 0 ## 6 1 20000 2 2 1 24 4 -2 0 0 ## 7 2 120000 2 2 2 26 9 -1 0 2682 ## 8 2 120000 2 2 2 26 8 2 1000 1725 ## 9 2 120000 2 2 2 26 7 0 1000 2682 ## 10 2 120000 2 2 2 26 6 0 1000 3272 ## # ... with 179,990 more rows